
(PR článek)
Každá organizace generuje svou činností velké množství dat. Společnosti pracující se zákazníky shromažďují data o jejich nákupním chování; organizace veřejné správy a vládní instituce pracují s daty o obyvatelstvu, jeho demografickém, pracovním, ekonomickém nebo zdravotním stavu; průmyslové podniky monitorují průběžně stavy různých zařízení a systémů a samo IT produkuje další data o tom, jak správně či chybně pracuje. Takovýchto dat přibývá stále rychleji, údajně 80 % jich vzniklo za poslední 2 roky, jejich velikost se celosvětově odhaduje na biliony terabytů, a tak hovoříme o fenoménu velkých dat, tedy Big Data.
(Ne)možnosti práce s Big Data
Pro uchování velkých dat existuje řada systémů, jako např. hadoop clustery, což jsou nákladově výhodné, distribuované, souborové systémy pracující na běžně dostupných platformách či celopodnikové datové sklady založené na technologiích různých výrobců. Většina dnešních řešení Big Data je tedy orientována na zpracování masivních objemů dat. Business uživatelé ale potřebují pro smysluplné analýzy a reporty přístup nejen k těmto velkým datům ale i k dalším zdrojům dat z provozních systémů, spreadsheetů, pomocných systémů či internetu.
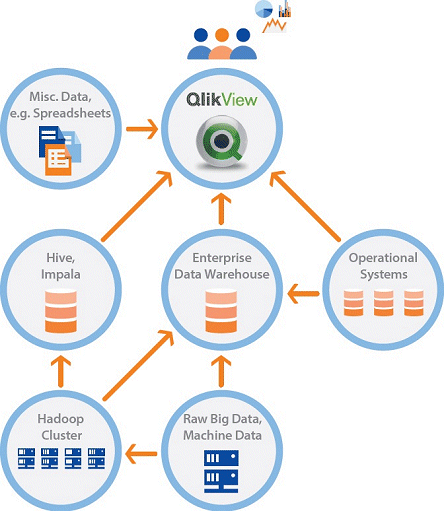
Stávající systémy pracující s Big Data nejsou obvykle navrženy pro analýzy řízené uživateli (user-driven analytics), ale jsou převážně orientovány na škálovatelnost, a nikoli výkon – vyřizování analytických dotazů je proto velmi pomalé. Navíc jednotlivé dotazy vyžadují napsání příslušných programů a není tedy podporován koncept ad-hoc dotazů.
Podobně je to s tradičními nástroji Business Intelligence (BI) závislými na součinnosti IT. V nich jsou pro předem očekávané dotazy připravena příslušná datová schémata, jednotlivé dotazy jsou řešeny lineárním vnořováním po předdefinovaných cestách. Uživatel tak nemá možnost svobodné volby a jím požadované změny pak trvají dlouho a jsou nákladné.
Práce s Big Data lépe a snadněji
Potřeby analytického uživatele proto mnohem lépe splňují systémy podporující tzv. in-memory asociativní analýzu, jejichž představitelem je nástroj QlikView od společnosti Qlik. V tomto prostředí uživatel samostatně rozhoduje, kde své dotazování započne a jak jej bude dále rozvíjet, má k dispozici veškerá data, která jsou uložena v operační paměti, a požadované dotazy a změny jsou proto extrémně rychlé a efektivní. Možnosti tohoto nástroje tak překračují běžně chápaný obsah pojmu Business Intelligence a definují novou oblast, tzv. Business Discovery. Nástroj této kategorie musí umožňovat uživateli, aby mohl samostatně pokládat následující dotazy na základě výsledků dotazů předchozích.
In-memory prostředí a Big Data
Data v prostředí in-memory architektury jsou v průměru komprimovány v poměru 1:10, takže např. při kapacitě 256 GB serverové paměti to představuje možnost pracovat s více než 2 TB vstupních dat, což umožňuje analýzy milionů řádek dat s vteřinovými odezvami. 2 TB dat nejsou málo, ale stále se nejedná o Big Data, jak jsou definována výše.
V prostředí QlikView je pro práci s externí Big Data infrastrukturou využita funkčnost, tzv. Direct Discovery. Jedná se o hybridní přístup, který umožňuje propojit in-memory data s daty získanými dynamickými dotazy z externích zdrojů. Agregované výsledky dotazů jsou zaslány do objektů QlikView, aniž by byly nataženy do jeho datového modelu. Tento výsledek tak umožňuje asociativní operace se všemi daty.
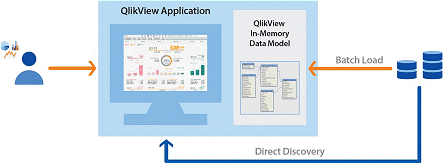
Business uživatel pracuje s Big Data bez znalosti programování a v kontextu s ostatními daty, v případě potřeby je zachována možnost drilovat až na příslušný detail. To, kdy je využita funkce Direct Discovery, může uživatel poznat pouze tak, že vyřízení příslušného dotazu není tak okamžité, jak je při práci s daty in-memory zvyklý. Toto „zpomalení“ je možné ale ovlivnit jak návrhem architektury řešení, tak možností „kešovat“ (rovněž v in-memory) výsledky externích dotazů pro rychlejší znovupoužití. V in-memory jsou proto obvykle alokována data, která jsou uživatelem z hlediska četnosti používána často (detailní data za aktuální období, relevantní a kontextová data, agregované, sumární či průměrné údaje za definovaná období), zatímco data, která jsou uložena v rozsáhlých faktových tabulkách, které nelze do in-memory uložit nebo přístup k nim je předpokládán s minimální četností, jsou ponechána v externích zdrojích.
Tato nová funkcionalita nástroje QlikView tak umožňuje využít nástroj kategorie Business Discovery i pro oblast Big Data. Není náhradou in-memory technologií ale jejich doplněním pro přístup k externím datům.
Autor: Tomáš Třmínek, Key Account Manager, trminek@komix.cz, KOMIX s.r.o.

Více informací o řešení: www.analyzyareporting.cz








































 PŘEDPLATNÉ
PŘEDPLATNÉ
 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU