
V prvním díle představíme vizi sémantického webu a různé formy sémantických informací, které už na webu běžně používáme, aniž si to uvědomujeme.
Rychlý růst internetu a webu v průběhu devadesátých let uspokojil do značné míry poptávku po informacích, ale nesplnil všechna očekávání expertů. Jedním z nich byl a je sir Tim Berners-Lee, který v roce 2001 publikoval v časopise Scientific American článek „The Semantic Web“, ve kterém formuloval vizi inteligentnějšího webu založeného na sémantických technologiích.
Vize sémantického webu
Tim Berners-Lee popsal v roce 2001 vizi sémantického webu, ve které funguje počítač jako osobní asistent, který svého majitele důvěrně zná a dokáže mu například doporučit a naplánovat celou dovolenou (včetně rezervace hotelu) v souladu s jeho časovými možnostmi a preferencemi. Takovéto možnosti byly v oblasti umělé inteligence slibovány odnepaměti, ale nikdy nedošlo k jejich naplnění. Sémantický web nespoléhá na pokročilou umělou inteligenci, která dokáže význam slov a tvrzení zpracovat sama, ale doporučuje obohacovat klasický web o značky a výroky psané ve speciálních jazycích (například RDF a OWL).
Sémantické informace vpletené do běžného webu umožňují počítači manipulovat s daty inteligentněji. Například slovo „auto“ vyskytující se na běžném webu je pro počítač pouze řetězec čtyř znaků. Na sémantickém webu je možné označit slovo „auto“ identifikátorem (URL) pojmu auto v nějakém popisu pojmů a jejich vztahů, kterému se běžně říká ontologie.
Počítač pak v ontologii například zjistí, že auto je dopravní prostředek, že má řidiče a že řidič je člověk, který má řidičský průkaz. Vyskytuje-li se pak v textu třeba informace „Petr jel autem do práce“, je pro počítač snazší odvodit, že Petr je člověk, který má řidičský průkaz.
Nejdříve ale musí existovat ontologie, která takové vztahy popisuje, a text musí být anotovaný (doplněný o značky). Tvorba ontologií většinou probíhá ručně. Automatické odvozování ontologií je stále předmětem aktivního výzkumu. Podobně je tomu se značkováním – často probíhá ručně, ale existuje i spousta automatických a poloautomatických nástrojů.
Sémantické spektrum
Ontologie je většinou definována jako explicitní popis konceptualizace. To jest, zaznamenává pojmy a jejich vztahy v nějakém jazyce. Tyto jazyky mívají velkou vyjadřovací sílu a často vyžadují expertní znalosti. Existují ale i méně silné a daleko rozšířenější prostředky pro popis konceptualizace. Používá je někdy téměř každý uživatel dnešního webu – jsou to tagování, taxonomie a tezaury.
Tagování neboli přiřazování štítků (kde štítek je obyčejný řetězec znaků) má nejmenší vyjadřovací sílu – význam zprostředkovaný tagováním je jen malý. Tagování na webu pomáhá uživateli třídit informace především za účelem jejich pozdějšího vyhledání.
Taxonomie je hierarchie (strom) pojmů. Většinou popisuje pouze jeden druh vztahu (například vztah „je podtřídou”), ale může v ní implicitně existovat více druhů vztahů, jako je tomu například u adresářů v souborových systémech. Podadresář P může být v nadřazeném adresáři N, protože P (jezevčík) je druhem N (pes). Jiný podadresář Q může být v nadřazeném adresáři N, protože Q (hlava) je částí N (pes).
Tezaurus také popisuje hierarchii pojmů, ale jasně říká, které vztahy mezi pojmy popisuje. Většinou jsou to pojmy „je obecnější než,“ „je méně obecný než“, „je příbuzný“.
Ontologie je nejbohatším způsobem popisu konceptualizace. V ontologických jazycích, jako je např. OWL, je možné zavádět jak pojmy, tak i nové vztahy, které jsou následně používány pro další popis pojmů. Tagování, taxonomie, tezaurus a ontologie tvoří takzvané sémantické spektrum (někdy se místo tagování uvádí obyčejný a řízený slovník).

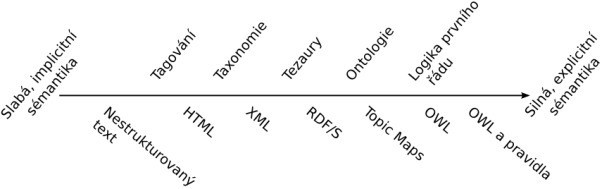
Sémantické spektrum v praxi
Dříve se k organizaci informací na webu i v společnostech používaly převážně předem definované taxonomie pojmů. Takováto a priori kategorizace je neflexibilní, protože nutí uživatele přizpůsobit se jednomu úhlu pohledu. Nejednou se uživateli stane, že by rád určitý soubor zařadil do dvou různých adresářů, aniž by ho musel kopírovat.
Tento problém řeší přiřazování štítků (jako například v Gmailu) – jednomu souboru mohu přiřadit mnoho štítků vlastního výběru (tj. z neřízeného slovníku). Díky tomu pak informace snáze najdu za pomoci fasetového vyhledávání. To už zjistili majitelé mnoha internetových obchodů: Zadáním štítku omezím výběr na produkty s tímto štítkem a mohu postupně přidávat další štítky, které produkt musí mít, a tak postupně zpřesňovat svůj výběr. Místo štítkování může obchod popsat produkty pomocí ontologie.
Ontologie popíše hierarchii (druhů) produktů, jejich vztahy a vlastnosti a obchod zařadí produkty do příslušných kategorií a vyplní jejich vlastnosti. To umožní zprostředkovat uživateli ještě inteligentnější vyhledávání v podobě zadávání intervalů, čísel ve správných jednotkách na základě informací, které jsou o jednotlivých kategoriích a atributech v ontologii.
Ačkoliv je sémantický web vyvíjen už více než deset let a dosažení jeho vize je stále v nedohlednu, mnoho z jeho myšlenek a technologií je v praxi už používáno. Jedním příkladem je již zmíněné fasetové vyhledávání. Mezi jiné patří například zobrazování tzv. rich snippets“ vyhledávači.
Rich snippets nejsou nic jiného než kousky informací doplněné o sémantické anotace, které vyhledávači sdělí, že daná informace je popis produktu, vizitky, události nebo struktury určitého webu. Ne vždy se ovšem firmy hledající praktické řešení shodnou s akademiky na způsobu anotace. Například vyhledávače se v roce 2011 spojily a zavedly schema.org – soubor schémat pojmů, který umožňuje jednoduchý popis obsahů stránek. Akademici záhy poskytli způsob jeho transformace na standardní, expresivnější, ale mírně složitější sémantický formát (www.schema.rdfs.org/).
Výhoda expresivnějších formalismů spočívá v možnosti tvořit bohatší popisy, které následně umožňují zajímavější automatické uvažování, jež je potřeba k dosažení vize, kterou popsal Tim Berners-Lee.
Autor je spoluzakladatel startupu TalentHacker.com







































 PŘEDPLATNÉ
PŘEDPLATNÉ
 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU